Huginn指南:为任意网站制作RSS
Huginn使用多个不同功能的Agent组合搭配来实现一系列功能,一个Agent可以执行特定的操作,并产生一个Event,你可以指定他产生的Event由哪个Agent接收处理。
比如我们需要使用WebSite Agent来爬取某个网站上的列表内容,爬取后列表的每一项会生成一个Event,我们可以指定一个Output Agent来接收这些Event,并将其转换为RSS的格式进行输出,复制Output Agent返回给你的URL就可以进行订阅啦,Huginn爬取网站生成RSS的基本原理就是这样。
Huginn爬取普通网页制作RSS
右键网页打开开发者工具,屏幕会分出一部分空间显示开发者工具窗口,点击左上角的按钮再把鼠标移动到页面上可以选择页面的某一个元素,比如这里我们要爬取推荐文章列表,推荐文章列表的每一项都有同样的样式,我们可以使用CSS选择器来指定爬取该项
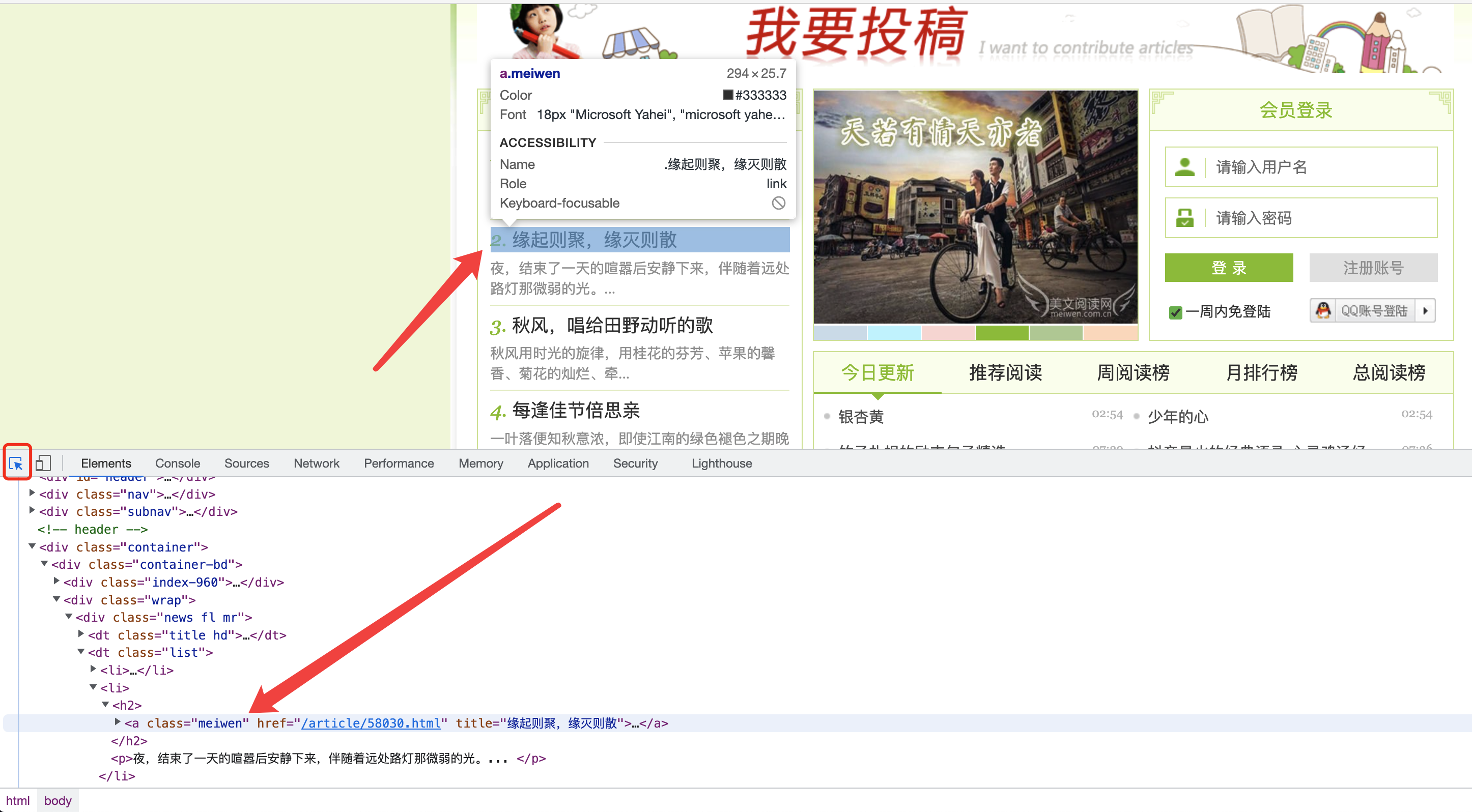
该元素可以用CSS选择器.meiwen选择到。
Tips: class=xxx则使用.xxx,如果为id=xxx则使用#xxx
该标签是a标签,我们可以继续限定一下条件,使用a.meiwen
如果要限制必须是h2 标签下的带有meiwen的class属性的a标签,可以使用h2 a.meiwen
如果要再加一个限制,是列表元素li下面的h2标签里带有meiwen的class属性的a标签,可以使用li h2 a.meiwen
添加其他附加限定条件以此类推
你也可以在右侧Style面板里点击加号添加一个自定义样式,输入CSS选择器,浏览器会自动高亮符合条件的网页元素,你可以使用这个功能来检验你写的CSS选择器是否正确以及是不是提取的你想要的内容
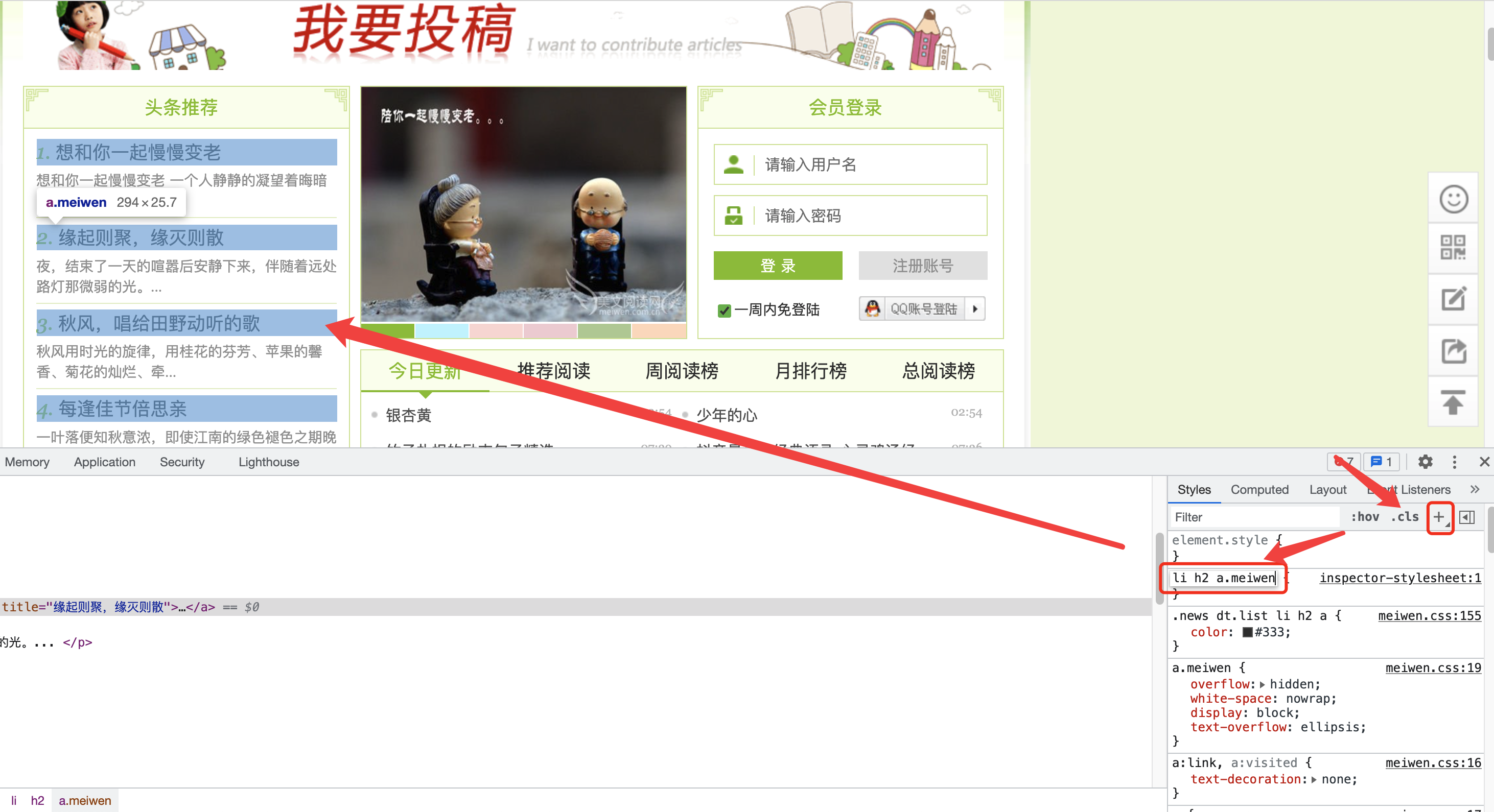
接下来在Huginn里创建一个Scenario,然后点击新建一个Agent,类型选择WebSite Agent,填写一个名称,并在最下面的配置处指定你要爬取的网页元素
Website Agent
The Website Agent scrapes a website, XML document, or JSON feed and creates Events based on the results.
url: {
css: li h2 a.meiwen
value: @href
}
以爬取url为例,css表示使用css选择器选择网页元素,value表示从哪里获取对应的值,对于刚才我们选取的一个元素来说
<a class="meiwen" href="/article/58030.html" title="缘起则聚,缘灭则散">缘起则聚,缘灭则散</a>
href属性里面的内容是他的链接,title属性里面的内容则是他的标题。接下来在value中填写@href指定从href属性提取内容,就可以取到链接地址了
Pro Tips:
如果是纯文本节点或是想提取标签内嵌的文本,value里可以填写
string(.)如果想删除多余的空格,可以使用
normalize-space(.)Pro Tips 2:
字符串处理函数和标签属性值变量可以一起使用,如
normalize-space(@title)可以获取该标签的title属性值并删除多余的空白字符
接下来点击Dry Run按钮进行测试,不出意外我们会得到一个json的输出,里面包括我们爬取到的每一项他的url和title。
如果没有成功,你可能需要删掉上面没有使用到的hovertext节点,因为该项指定的内容在我们刚才的网页中并不存在。
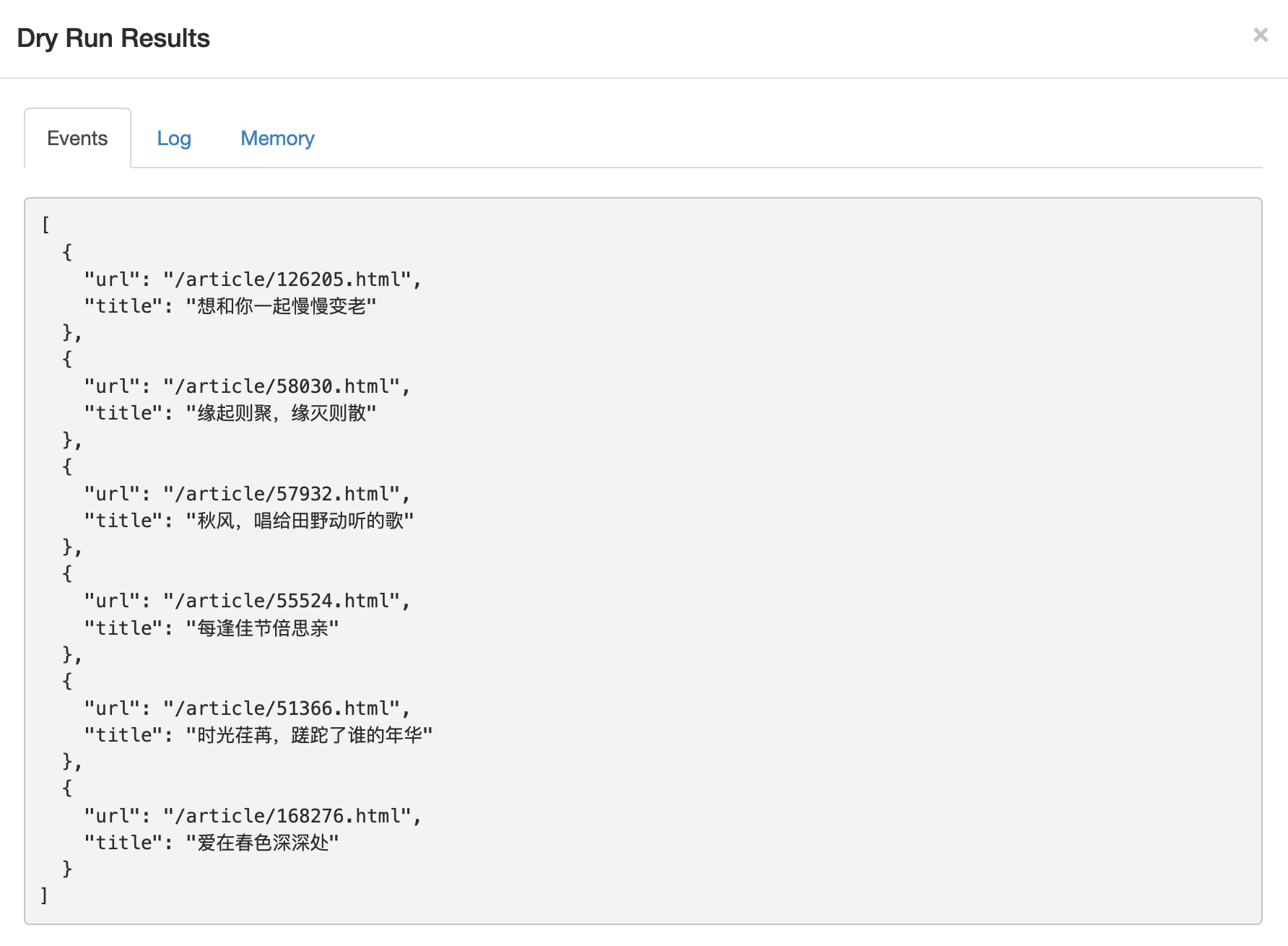
点击Save保存,我们开始下一步输出RSS。在刚才的Scenario中再新建一个Agent,选择Data Output Agent,并设置他的名字和Source Agent
Data output Agent
The Data Output Agent outputs received events as either RSS or JSON. Use it to output a public or private stream of Huginn data.
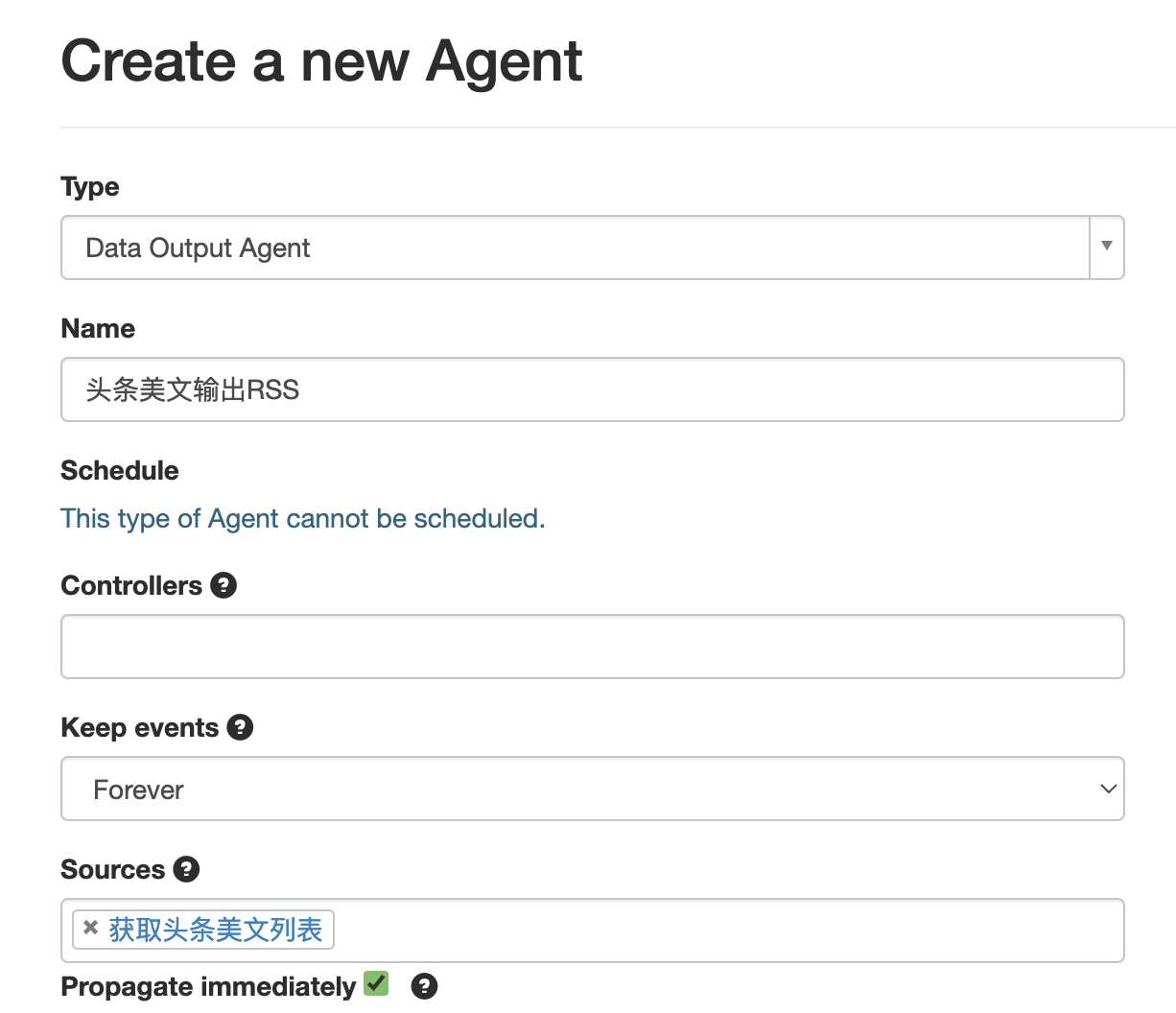
Propagate immediately是指即时处理来自Source Agent的Event,启用他方便我们调试,但会略微增加服务器负载,你可以自行决定是否使用。

在secret字段中为你的这个RSS标注一个英文的名字,修改title字段标注你的RSS的名字。item字段是每条文章会有的属性,一般来说主要就title和link,分别设置为上文我们提取的值的变量名。这里添加一个guid字段,这是一篇文章的唯一标识符,避免RSS阅读器读到的文章标题不同但是内容相同,常见于某篇文章的标题被修改,这会导致RSS阅读器内出现多篇重复文章。
此外建议增加一个link字段,值设置为与爬取的网站的主域名一致,避免网站内使用相对链接开头的资源无法正常加载。
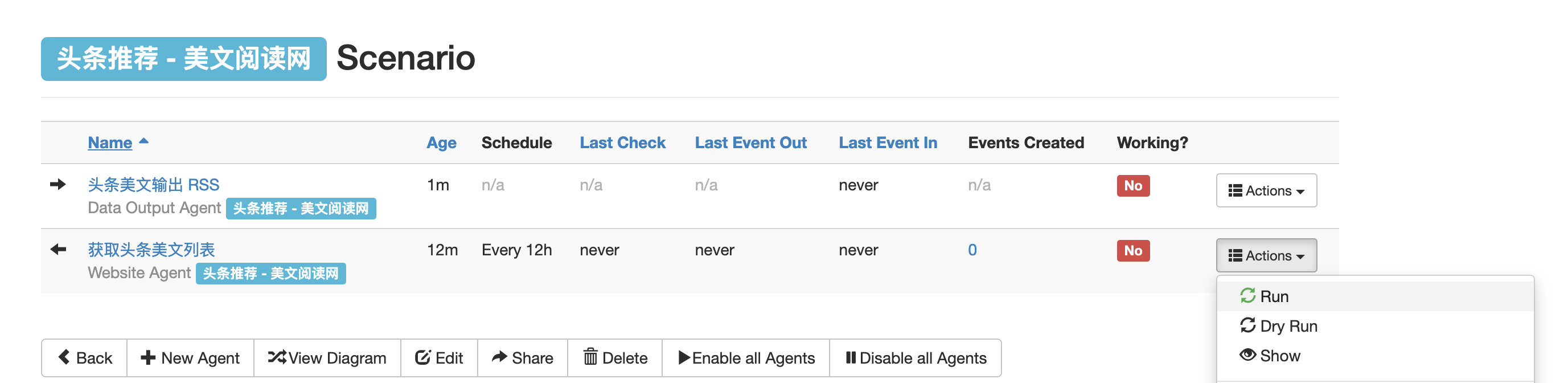

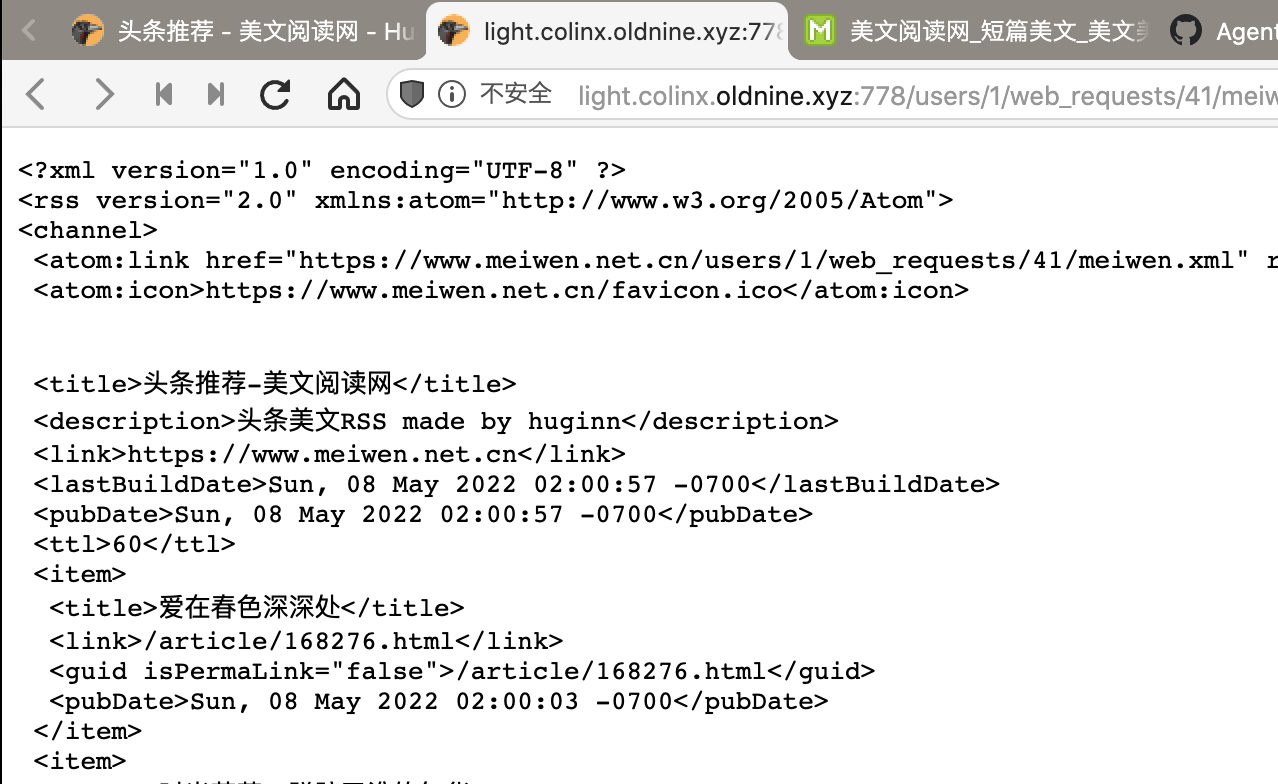
点击Save保存,回到Scenario界面,第一次需要手动点击运行一下刚才的Website Agent。稍等片刻后台会进行爬取,右上角会显示产生了多少个Event。再点开刚才设置的Data Output Agent查看详情,vola!右侧就会显示生成的RSS链接了,复制以xml结尾的链接到RSS阅读器中就可以订阅啦🎉
如果你的配置正确但是WebSite Agent又没有输出任何内容的话,那么你要爬取的站点的内容应该是通过JavaScript在你带开浏览器时动态生成的。
Pro Tips:
你可以右键网页在开发人员菜单中点击显示源代码,然后用Ctrl+F搜索你在页面上见到的想爬取的某一条内容,如果有说明该网站的页面时静态的,否则说明你要爬取的内容并不是静态的。
要爬取这样的站点,我们需要模拟浏览器操作,执行页面上的JavaScript脚本,待数据生成完毕后再使用上面的方法去爬取内容。要模拟浏览器操作,这里介绍两个方案:一个是利用browserless的无头浏览器,另一个是使用在线PhatomJS服务。
使用Huginn+Browserless为动态网页生成RSS
部署了RSS Man X的完整版的话默认已经包含huginn和browserless服务,无需重复安装。且huginn可以通过service.browserless:3000访问到browserless服务。
总体步骤与上文一样,不过因为被抓取的内容是通过JavaScript动态生成的,所以直接使用WebSite Agent是抓取不到东西的,我们需要先使用Post Agent向browserless服务发送指令,让他帮我们模拟浏览器操作,再将最终完整的网页返回给我们,再使用WebSite Agent进行后续处理。
Post Agent
A Post Agent receives events from other agents (or runs periodically), merges those events with the Liquid-interpolated contents of payload, and sends the results as POST (or GET) requests to a specified url. To skip merging in the incoming event, but still send the interpolated payload, set no_merge to true.
接下来以这个网站为例介绍一下,这个列表页的内容是由JavaScript动态生成的
按照以下内容设置你的Post Agent
{
"post_url": "http://service.browserless:3000/content",
"expected_receive_period_in_days": "1",
"content_type": "json",
"method": "post",
"payload": {
"url": "https://pccz.court.gov.cn/pcajxxw/pcgg/ggdh?lx=0"
},
"headers": {
"Cache-Control": "no-cache",
"Content-Type": "application/json"
},
"emit_events": "true",
"no_merge": "false",
"output_mode": "clean"
}
其中post_url为你的browserless实例地址,如果你使用了RSS MAN X里的Huginn可以直接向上面一样填写。payload中的url字段填写你需要的网页地址。注意emit_events要设置为true,这样才方便我们后续使用WebSite Agent操作。
点击Dry Run,如果能返回一个带有body字段且里面有文本内容说明调用成功。
调用不成功检查一下配置,以及是不是我们的爬虫被目标网站拦截了。若是爬虫被拦截可参考文末的解决方案。
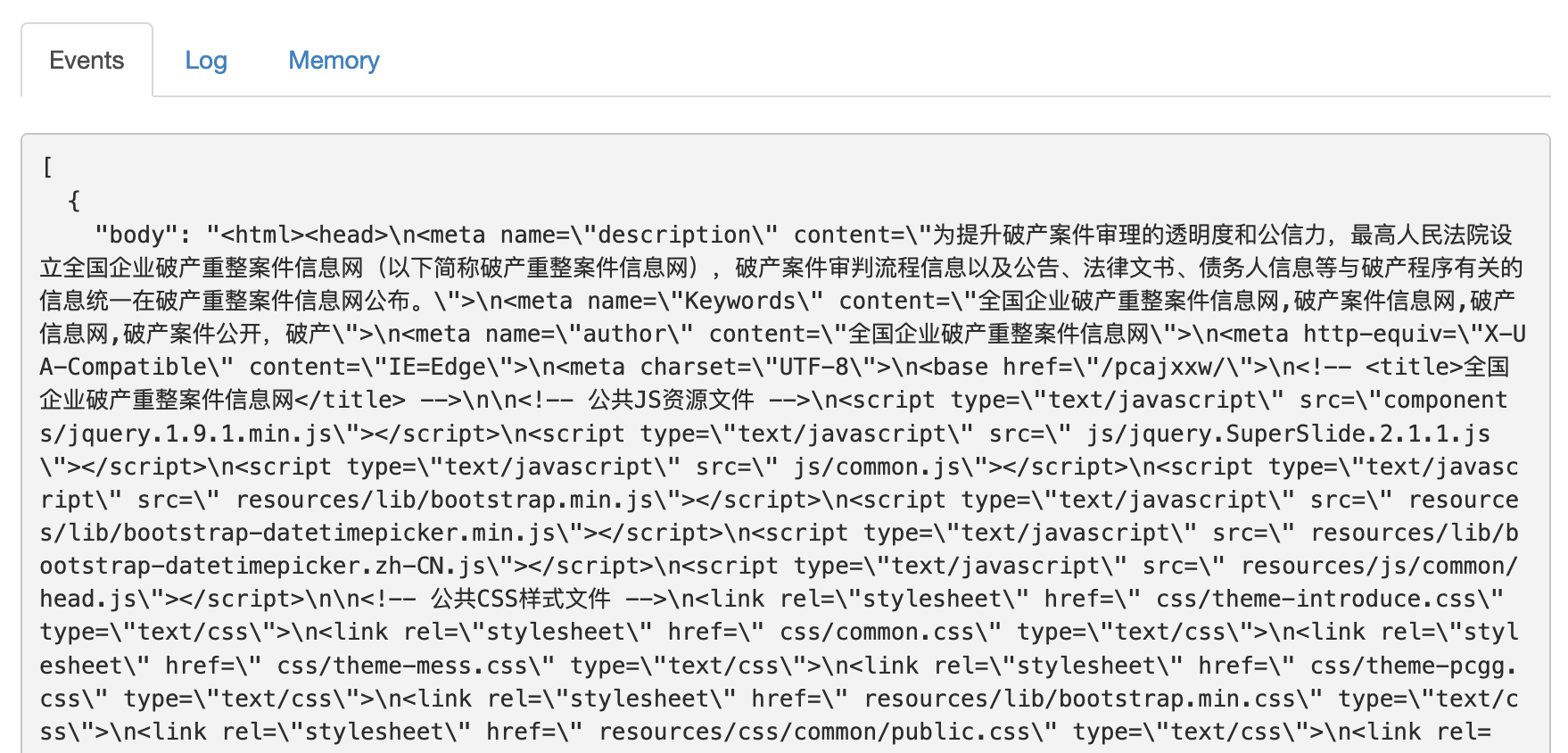
接下来点击Save保存,再新建一个Website Agent,Source设置为刚才的Post Agent。
{
"expected_update_period_in_days": "2",
"data_from_event": "{{ body }}",
"type": "html",
"mode": "on_change",
"extract": {
"url": {
"css": "ul#wslb li a",
"value": "normalize-space(@href)"
},
"title": {
"css": "ul#wslb li a",
"value": "@title"
},
"author": {
"css": "ul#wslb li div.center",
"value": "normalize-space(.)"
}
}
}
注意修改data_from_event的值,其他地方与爬取普通网站一样。再新建并配置一下Output Agent,RSS的链接就出来了
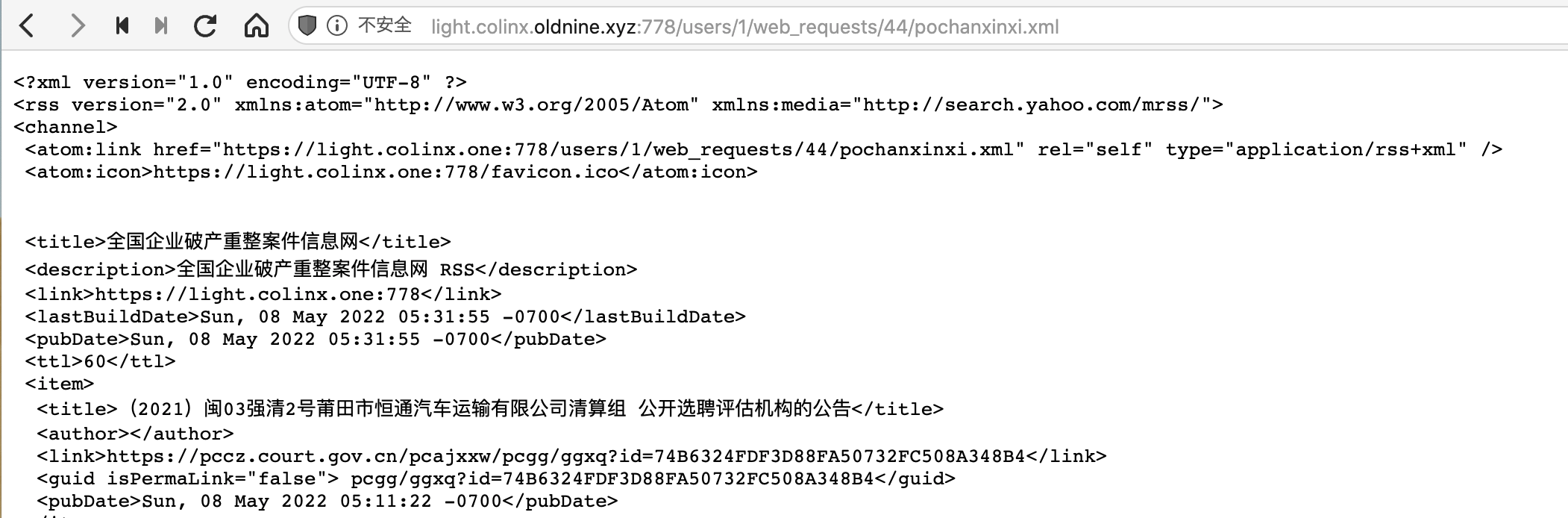
使用PhantomJS为动态页面生成RSS
首先需要到Phantom Js Cloud的官网注册一个账户,每个账户官方提供了一定的免费额度,每天大概可以爬取500个页面,对于做RSS来说妥妥的够用了。注册之后可以得到一个API KEY,这个待会会使用到。
接下来新建一个Phantom JS Cloud Agent,填写基本的名称、API KEY和目标URL,render type选择html。底下User Agent建议改用真实的浏览器UA,减少触发反爬虫的可能性。如果不知道自己的UA可以到这个网站查看当前浏览器的UA,复制字符串即可。如果懒得查也可以用这个
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.81 Safari/537.36
Phantom JS Cloud Agent
This Agent generates PhantomJs Cloud URLs that can be used to render JavaScript-heavy webpages for content extraction.
URLs generated by this Agent are formulated in accordance with the PhantomJs Cloud API. The generated URLs can then be supplied to a Website Agent to fetch and parse the content. Sign up to get an api key, and add it in Huginn credentials.
点击Dry Run后会返回一条url,返回格式类似这样
[
{
"url": "https://phantomjscloud.com/api/browser/xxxxxxx"
}
]
之后创建一个WebSite Agent,Source Agent设置为上面的Phantom JS Cloud Agent,然后稍微改一下url的部分
{
"expected_update_period_in_days": "2",
"url_from_event": "{{url}}",
"type": "html",
"mode": "on_change",
"extract": {...}
}
注意将原来的url:??的部分更改为"url_from_event": "{{url}}",这样就指定使用Phantom JS Cloud为我们获取的完整网页,接下来的操作就大同小异了。配置好要爬取的字段和规则后点击Dry Run就可以看到结果
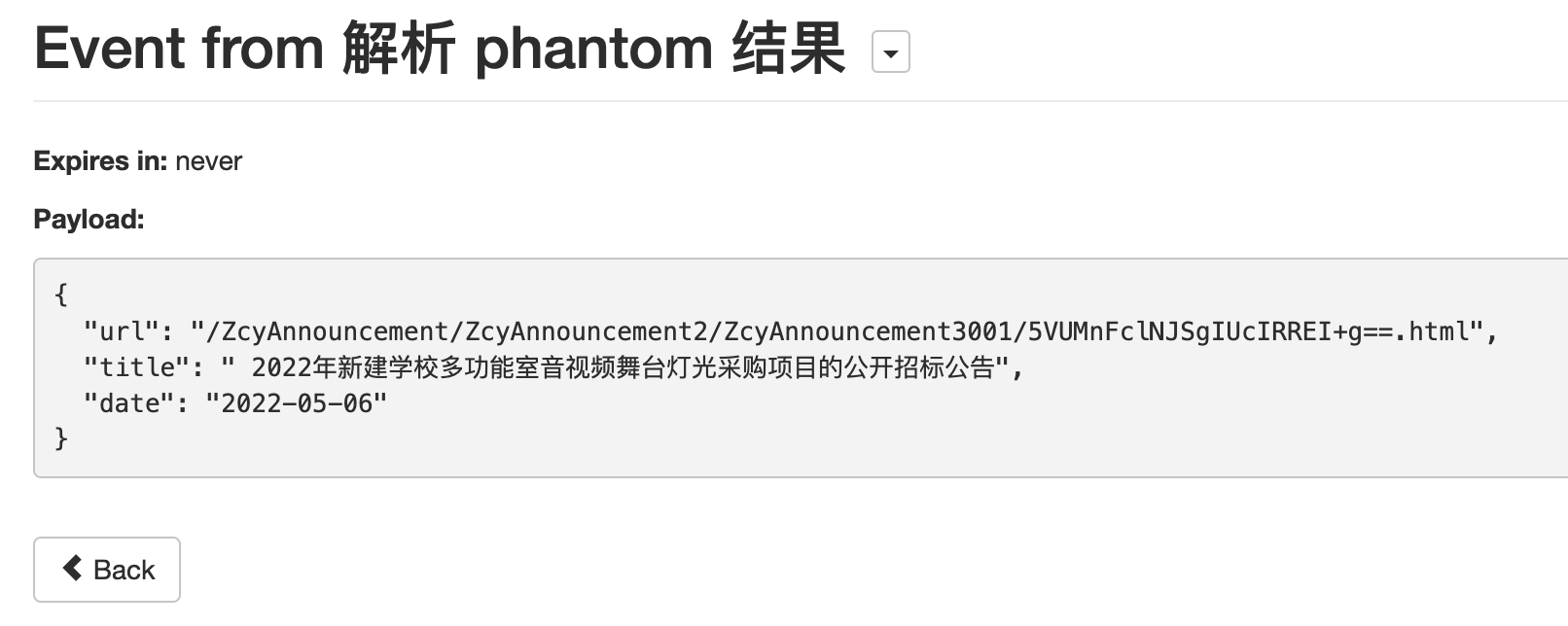
这里是刚才的Agent产生的一个Event。这里除了url和title我还提取了date字段。在Output Agent中,可以配置为每一条文章输出发布时间的信息。对于这种规整的日期字母串,可以使用{{ date | date: %F }}进行解析并格式化输出为rss规范的时间格式如果没有配置的话,每篇文章的发布时间显示的都是一样的,为Huginn爬虫更新的时间。
"item": {
"title": "{{title}}",
"link": "{{url}}",
"pubDate": "{{ date | date: %F }}"
},
Pro Tips:
Huginn解析日期
注意
{{ date | date: %F }}里面,第一个date是上面的Website Agent产生的Event里面的变量名,第二个date是Huginn使用的Liquid模版引擎语法里内置的一个filter,可以理解为有特定功能的函数
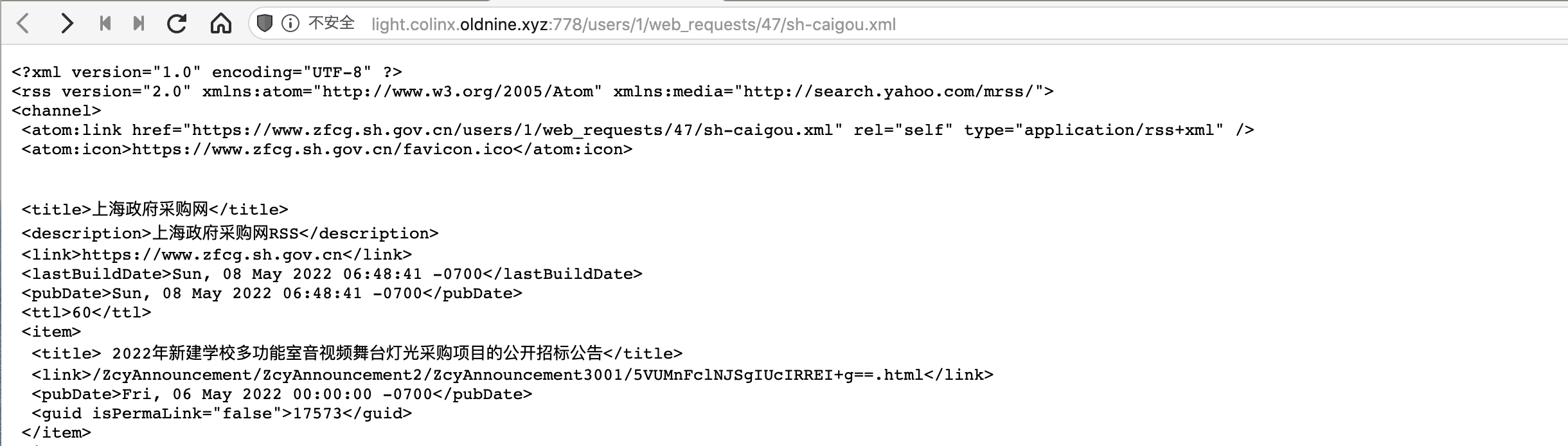
FAQ
- 为什么启动docker容器后访问Huginn显示网络错误?
Huignn冷启动较慢,需要等待三五分钟。如果还是不行,检查端口映射和防火墙设置
- 为什么抓取到的包含相对路径的结果,网页上可以点击访问,但是生成的RSS不能正常使用?
检查link的设置,有些网站只是域名,有些网站有子目录,具体查看该网页源码中head节点里base url的设置
- 如何对爬取到的某一项的字符串做更高级更复杂的处理?
可以参考Hugnn官方对Liquid语法的文档以及Shopify官方关于Liquid模板的语法文档
- 为什么部署了Huginn,等了很长时间都无法访问后台页面?
若部署后某个应用一直无法通过浏览器访问,请检查是否绑定到了6000/6666等特殊端口,浏览器会拦截对这些端口的访问参见这里
- Huginn 爬虫访问目标网站被拦截了怎么解决
介绍几个基本的反反爬虫策略:- 带上User Agent,要求是真实的浏览器UA。
- Browserless去掉默认会和请求一起发送的可以被识别为爬虫的特征参数,设置browserless的环境变量
DEFAULT_HEADLESS=false - 使用随机代理IP,适用于因爬取频率达到爬虫阈值